データ統合とETLの主な違いは、データ統合は異なるソースのデータを組み合わせてユーザーに統一されたビューを提供するプロセスであり、ETLはデータウェアハウス環境でデータを抽出、変換、ロードするプロセスであることです。
データ統合は、異なるソースからのデータを組み合わせて、意味のある価値ある情報にすることを意味します。
したがって、完全なデータ統合ソリューションは、異なるソースから信頼できるデータを提供します。
複数のシステムを統合し、アプリケーションを統合してデータの統一ビューを提供する際に重要なプロセスです。
一方、ETLは、データをデータウェアハウスに格納する前に行われるプロセスです。
これは、データの抽出、変換、読み込みを含みます。
データ統合とは
データ統合は、異なるソースにあるデータを結合して、ユーザーに統一されたビューを提供するプロセスです。
しかし、データ統合はアプリケーションによって異なる。
商用アプリケーションでは、2つの組織がそれぞれのデータベースを統合することができる。
バイオインフォマティクス・プロジェクトのような科学的なアプリケーションでは、様々なリポジトリからの研究結果を1つのユニットに統合することができる。
また、データ統合の一般的な用途は、データウェアハウスで大規模なデータセットを共有する必要のあるビッグデータの分析である。
このように、データ統合は難しい作業です。
また、リレーショナルデータベースやXMLデータベースなど、様々な統合システムに対応するための汎用性が求められる。
ETLとは
A data warehouse is a system that helps to analyze data, create reports and visualize them. The managers, data analysts, business analysts can analyze this data to take business decisions. There are three steps to follow before storing data in a data warehouse. It is called ETL. It involves data Extraction, Transformation, and Loading into the data warehouse.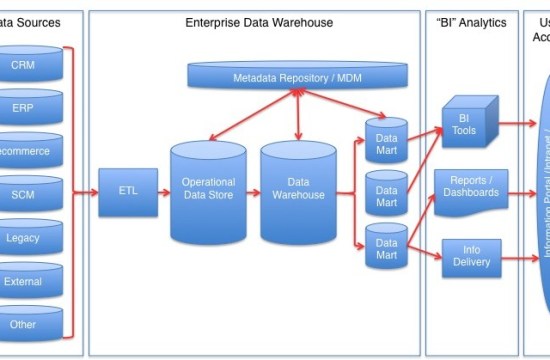
組織には様々なデータソースが存在します。
最初のステップは、これらの異なるソースからデータを抽出することです。
しかし、データ抽出は元のデータソースのパフォーマンスやレスポンスタイムに影響を及ぼしてはならない。
データを抽出する方法として、完全抽出と部分抽出があります。
第2段階は変換です。
ここでは、抽出されたデータをクレンジングし、マッピングし、有用な方法で変換する。
データ選択、マッピング、データクレンジングは、いくつかの基本的な変換技術です。
さらに、いくつかの高度なデータ変換技術もあります。
標準化、文字セットの変換とエンコーディングの処理、フィールドの分割とマージ、要約、重複排除などです。
最後のステップは、準備されたデータを取得し、データウェアハウスに格納することです。
これをロードと呼ぶ。
ここで、ロードには、初期ロード、増分ロード、フルリフレッシュがあります。
初期ロードとは、データベースを初めてロードすることである。
増分ロードとは、定期的に必要な変更を加えることであり、完全リフレッシュとは、1つまたは複数のテーブルのデータを削除し、新しいデータで再ロードすることである。
データ統合とETLの違い
定義
データ統合とは、異なるソースに存在するデータを結合し、ユーザーに統一されたビューを提供するプロセスです。
ETLは、データをデータウェアハウスに格納する前に行われる、抽出、変換、ロードの3つのステップからなる機能です。
使用方法
データウェアハウスがETLを使用するアプリケーションであるのに対し、科学や商業のアプリケーションはデータ統合を使用します。
これもデータ統合とETLの違いです。
結論
データ統合とETLの違いは、データ統合が異なるソースのデータを結合してユーザーに統一されたビューを提供するプロセスであるのに対し、ETLはデータウェアハウス環境でデータを抽出、変換、ロードするプロセスであることである。
