解析木と構文木の主な違いは、解析木が入力文字列を得るための文法の導出を表す階層構造であるのに対し、構文木はプログラミング言語の構文を木に似た階層的な形式で表現する方法である点です
構文木は、入力を具体的に表現したものです。
入力に関するすべての情報が含まれている。
一方、構文木は、プログラミング言語の構文を木として表現します。
コンパイラや後のコード生成に必要なシンボルテーブルの生成に役立つ。
パースツリーとは
パースツリーは、文脈自由文法に従って文字列の構文構造を表現します。
入力言語の構文が記述されています。
構文木は、異なるタイプの構成要素に対して異なる記号の形を使用しません。
構文木を構成する基礎となるのは、句構造文法や依存文法です。
自然言語文やプログラミング言語の処理で構文木を生成することが可能である。
また、フレーズマーカは、フレーズ構造を示す言語表現です。
木や括弧で囲まれた表現で表現する。
構文解析木に句構造規則を適用して句マーカを生成する。
構文的に曖昧な文に対する可能な構文木の集合は、構文林である。
シンタックスツリーとは
構文木は、プログラミング言語で書かれたソースコードの抽象的な構文構造を記述したものです。
中括弧やセミコロンなど、言語によっては文を終了させる要素ではなく、規則に着目している。
また、プログラミング文の要素をいくつかのセクションに分割した階層構造になっています。
ツリーのノードは、ソースコードに発生する構成要素を意味する。
実際の構文の細部まで表現しているわけではなく、構造ベースと内容ベースの細部を表現している。
文脈解析などの後続処理により、構文木にさらに情報が追加されます。
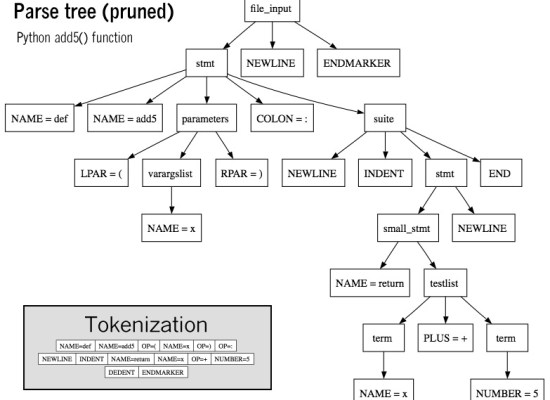
図2:ユークリッド・アルゴリズムのシンタックスツリー
構文木は、コンパイラの精度を判定するのに役立つ。
構文木にエラーがある場合、コンパイラはエラーメッセージを表示する。
また、プログラム解析やプログラム変換などにも利用される。
解析ツリーと構文ツリーの違い
定義
解析木とは、文脈自由文法に従って文字列の構文構造を表現した、順序付き、根付きの木のことである。
一方、構文木は、プログラミング言語で書かれたソースコードの抽象的な構文構造を木で表現したものです。
したがって、これが解析木と構文木の主な違いです。
同義語
解析木、導出木、具象構文木は解析木の別称であり、抽象構文木は構文木の別称です。
機能性
また、構文木がプログラミング言語の構文の記録であるのに対し、解析木は入力テキストにマッチするルール(トークン)の記録です。
この点も、解析木と構文木の大きな違いです。
結論
解析木と構文木の大きな違いは、解析木が入力文字列を得るための文法の導出を階層的な構造で表すのに対し、構文木はプログラミング言語の構文を階層的な木に似た構造で表現する方法であることです。
