ETLとデータウェアハウスの大きな違いは、ETLがデータを抽出、変換、ロードしてデータウェアハウスに格納するプロセスであるのに対し、データウェアハウスは複数のデータソースからの統合データを格納するために使用される中心的な場所であることです。
データウェアハウスは、データを分析し、レポートを作成し、可視化することでビジネス上の意思決定を行うためのシステムです。
主体志向、統合、時変、不揮発性です。
しかし、データをデータウェアハウスに格納する前に、いくつかのステップを踏む必要がある。
このプロセスはETLと呼ばれています。
これは、データを抽出し、変換し、最後にデータウェアハウスにそれらをロードすることを含む。
したがって、ETLとデータウェアハウスの違いは、この基本的な概念に起因している。
ETLとは
ETLとは、Extract(抽出)、Transform(変換)、Load(読み込み)の頭文字をとったものです。
このプロセスでは、まず、複数のデータソースからデータが抽出される。
次に、データを変換し、データウェアハウスにロードします。
ETLは、このプロセス全体を表します。
IBMデータステージ、Informatica、および、Microsoft Integration Servicesは、いくつかのエンタープライズレベルのETLツールです。
それでは、ETLの各ステップをより詳しく見ていきましょう。
抽出
抽出は最初のステップです。
データベースなどのさまざまなデータソースからデータを抽出する。
抽出を行う際に注意しなければならないのは、元のデータソースのパフォーマンスや応答時間に影響を及ぼしてはいけないということである。
そのため、様々なデータ抽出戦略があります。
完全抽出 – これは、すべてのデータソースからすべてのデータを抽出するものです。
この戦略の主な用途は、初期段階でデータウェアハウスをロードしたり、変更されたデータの識別が困難な場合にロードすることです。
部分抽出(更新通知あり) – この戦略は、完全抽出よりも簡単で高速です。
これは、変更されたデータのみを抽出するものです。
部分抽出(更新通知なし) – これは、特定の主要な特徴に基づいてデータを抽出するものです。
例えば、昨日までに抽出されたデータがある場合、今日のデータを抽出し、その中の変更点を特定することができる。
変身
抽出されたデータは生データであるため、あまり有用ではない。
そのため、次のステップでデータ変換を行う。
データのクレンジング、マッピング、変換を行う。
基本的な変換作業は以下の通りです。
選択 – 必要なデータを選択する
マッピング – さまざまなルックアップファイルからデータを検索し、変換が必要なデータをマッチングさせる。
データクレンジング – 標準化するためにデータをクリーニングする。
サマリゼーション – データの集約と統合
主なデータ変換作業は次のとおりです。
標準化 -データは様々なソースから来るので、標準化が必要である
文字セットの変換とエンコーディングの処理 – データを定義されたエンコーディングに変換する
値の計算 – 既存のカラムから新しいカラムを計算し、導出する。
フィールドの分割と統合 – 要件に応じて、フィールドを複数のフィールドに分割したり、複数のフィールドを1つのフィールドに統合したりします。
測定単位の変換 – データの時間変換などを含む。
サマライズ – データの集計や統合を行う。
重複削除 – 複数のソースから受け取った重複するデータを削除すること。
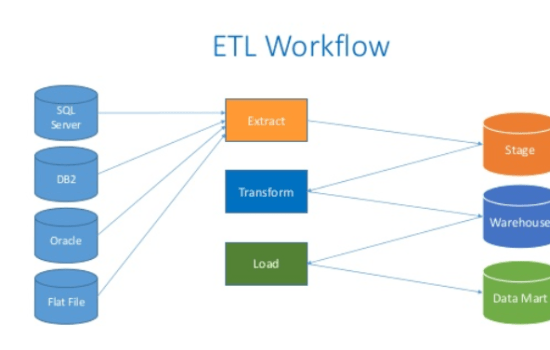
ロード
用意されたデータを取得し、データウェアハウスに格納する作業です。
様々なロード手法があります。
初期ロード – データウェアハウスを初めてロードする。
インクリメンタルロード – 必要に応じて継続的な変更を定期的に適用する。
フルリフレッシュ – 1つまたは複数のテーブルの内容を完全に消去し、新鮮なデータで再ロードする。
データウェアハウスとは
データウェアハウスは、ビジネスインテリジェンスのプロセスを支援するシステムです。
データを、ビジネスを分析するための意味のある情報に変換します。
したがって、組織の管理者が意思決定を行う際の貴重なリソースとなります。
また、組織は、MySQLやMSSQLなどの様々なデータベースを持っています。
これらのデータはすべて抽出され、変換され、データウェアハウスにロードされる。
その後、データは統合され、処理される。
最後に、データアナリスト、データサイエンティスト、および管理者が、このデータを使用して、ビジネス上の洞察を得る。
さらに、データウェアハウス内のデータは、データマートに分割される。
それぞれのデータマートには、特定のユーザー向けのデータが格納される。
これにより、セキュリティとデータの整合性が向上します。
通常、データウェアハウスは、通常の運用データベースとは別の場所に設置されます。
ETLとデータウェアハウスの違いについて
定義
ETLとは、データウェアハウス環境においてデータを抽出、変換、ロードするプロセスのことである。
一方、データウェアハウスは、企業の様々な業務システムによって収集されたすべてのデータを統合したリポジトリです。
したがって、これがETLとデータウェアハウスの基本的な違いです。
使用方法
ETLは、データウェアハウスに格納する前にデータを修正するために使用されるプロセスです。
データウェアハウスは、ビジネス上の意思決定を行うために使用されます。
さらに、データの品質と一貫性を高め、ビジネスインテリジェンスを向上させることができます。
したがって、ETLとデータウェアハウスには、個々の用途に応じた違いが存在する。
結論
ETLとデータウェアハウスの基本的な違いは、ETLはデータを抽出、変換、ロードしてデータウェアハウスに格納するプロセスであり、データウェアハウスは複数のデータソースからの統合データを格納するための中心的な場所であることです。
